
In July of 2020 I’ve joined the AI Residency program from HUB of Artificial Intelligence, in this program the AI residents perform proof of concepts (POC) for companies meanwhile have classes from researchers of Advanced Institute for Artificial Intelligence.
One of the challenges as an AI resident was to classify soybeans based on images in order to improve the selection of seeds. Soybean seeds are classified according to their qualities and it’s an important information to industry and soybean farmers because of the control quality.
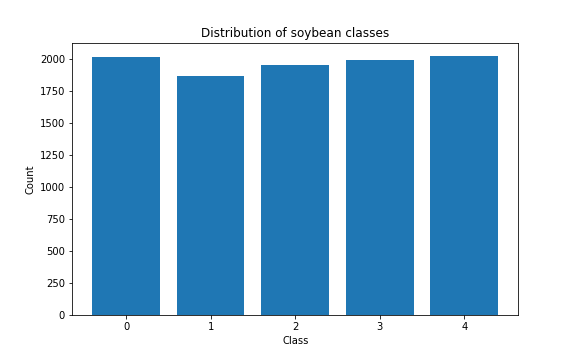
The data for this task contains 9.853 RGB images (150x150 px) of soybeans, each one of them belonging to one of four classes. The below image shows a sample of soybeans, images on the same row have the same class of seeds.

Fortunately, the distribution of soybean classes is well balanced.
Transfer Learning
Transfer learning is a machine learning method where a model trained in one task is reused for a different problem. One of the reasons to use transfer learning in deep learning is when the dataset is small and the network doesn’t have enough samples to learn the patterns to make a good prediction.
Any pre-trained model used in the same task (classification or regression) can be used in transfer learning. The general procedure to classification problems is to keep the same architecture of the original network, preserve the trained weights, modify the output layer according to the number of classes and then train the model with the new data.
![]()
There are plenty of models trained in specific tasks who achieved the State of The Art (SOTA) on image classification, object detection/segmentation and NLP; these are good candidates for transfer learning.
Proposed solution
Several transfer learning models were trained based on a pre-trained convolutional neural network (ResNet50) varying the hyperparameters and including data augmentation. Each training was tracked using MLflow to store the evaluation metrics and weights for soybean classification. All the models were trained using the Tensorflow package.
For evaluation, the holdout method with 20% for the test was used to evaluate the model accuracy.
Results
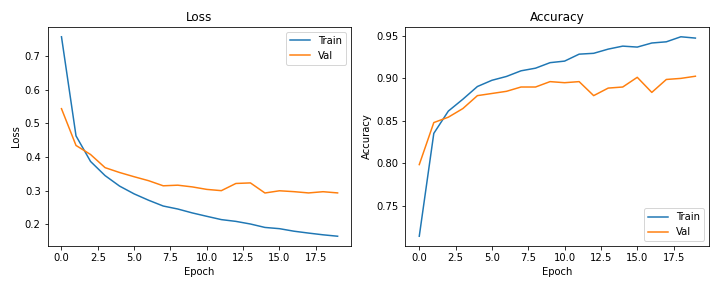
The best model was achieved training with batch size equals to 64 and learning ratio of 0.001. In only 20 epochs the loss and accuracy for validation data had no more improvements and achieved around 90% of accuracy.
Besides the good performance of the model, it’s important to notice that predictions of class 3 is slightly worse than others in terms of precision, since 52 and 36 seeds was misclassified as 3 when they are actually from class 1 and 2, respectively, even though the precision still high for class 3 (79%). The below image shows the predicted classes versus true classes.
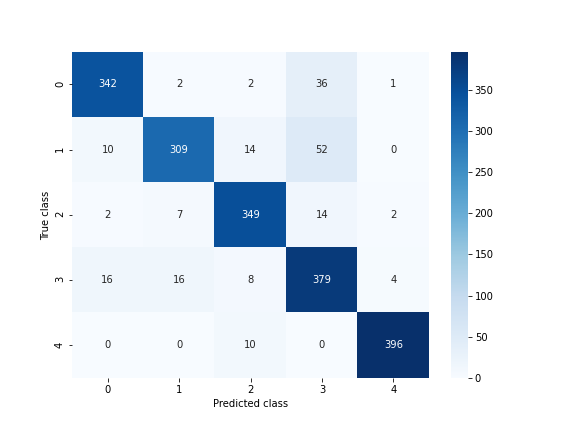
The proposed model achieves an overall accuracy of 90.05% for test data.
In conclusion it’s possible to classify soybean seeds based on images to improve the process of control quality keeping high accuracy in the process. The use of artificial intelligence can help us in manual tasks allowing humans to focus on tasks that require skills such as creativity, decision making, critical thinking and emotions where their expertise and human touch make a real difference.
In the next post I’ll show the visualizations and interpretations of convolutional neural networks using this problem as an example.
All the codes in this post and the solution for the challenge was designed using Python and are available in this repository on GitHub.
Feel free to comment or to send me an email.