
In the last weeks I’ve started a selection process in a data science course sponsored by Codenation. To join in this program it’s necessary to be approved on the selection challenge, which was to predict the math scores of students of ENEM 2016.
ENEM is a college entrance exam applied in Brazil, students can get a position in public universities or a financial support. ENEM is the second biggest exam in the world.
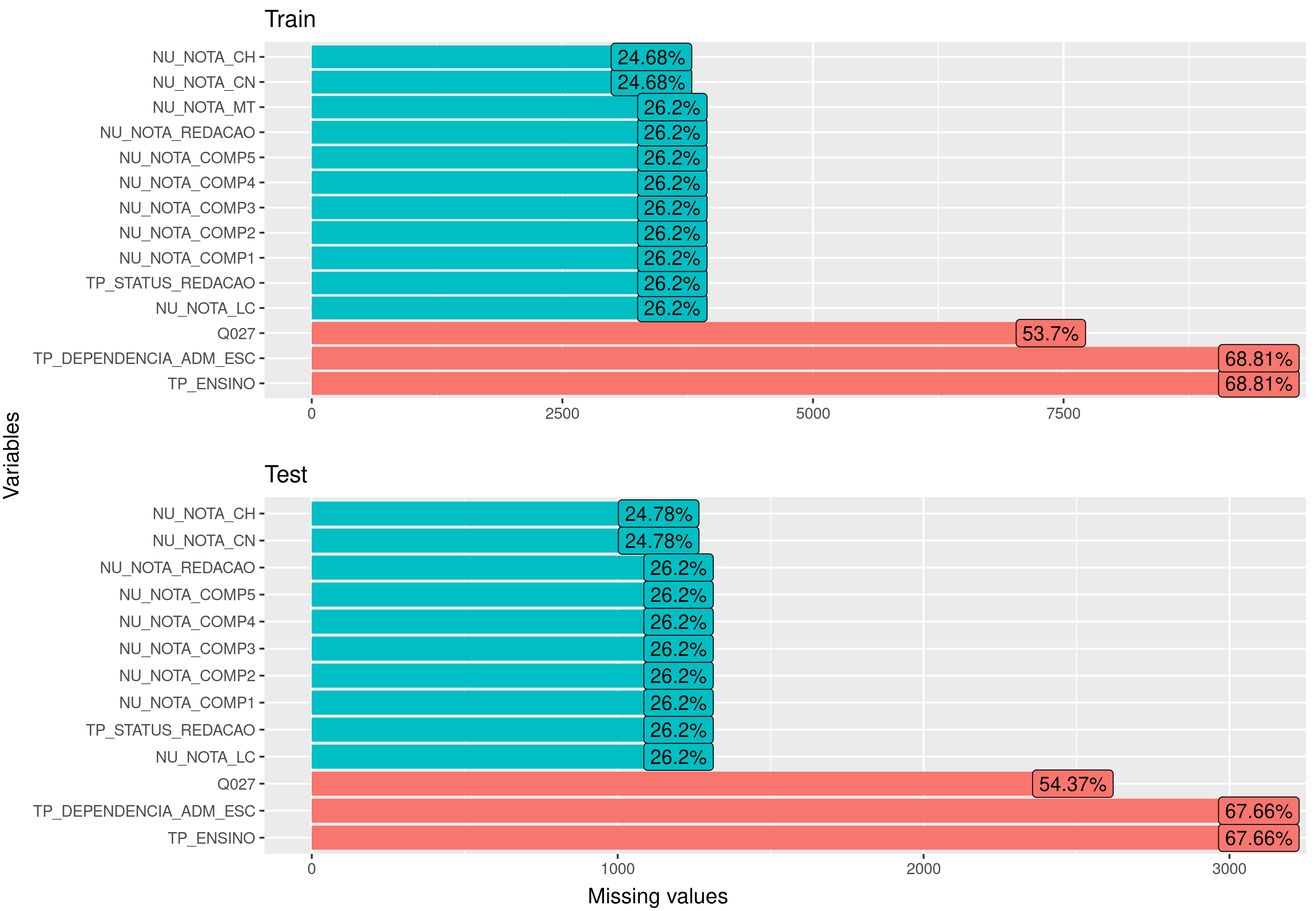
This problem caught my attention because of the missing values in test data. What’s the best solution when you have missing values in test data and it’s not possible to drop the missing values? should you ignore the features with missing values even if they are good predictors? Should you fill with a mean value or drop the observations?
Case study: Predict math score with missing values in test data
ENEM is an exam that has four tests and an essay, these are applied along two days.
The given data was a train and test split with information about the student’s profile, socioeconomics status, exam local and the test scores.
Since the math score is a quantitative variable, we are in a regression problem. With an exploratory analysis, we find out that the exams scores (human science, natural science and languages) seems to be good predictors for math score but, these variables has missing values on train and test data.
| Feature | Description |
|---|---|
| NU_NOTA_CH | Score in human science’s test |
| NU_NOTA_CN | Score in natural science’s test |
| NU_NOTA_COMP1 | Essay proficiency score 1 |
| NU_NOTA_COMP2 | Essay proficiency score 2 |
| NU_NOTA_COMP3 | Essay proficiency score 3 |
| NU_NOTA_COMP4 | Essay proficiency score 4 |
| NU_NOTA_COMP5 | Essay proficiency score 5 |
| NU_NOTA_MT | Score in math’s test |
| NU_NOTA_LC | Score in languages’ test |
| NU_NOTA_REDAÇÃO | Essay score |
| Q027 | What age did you start to work? |
| TP_ENSINO | Regular school, special school or education for teenagers and adults |
| TP_DEPENDENCIA_ADM_ESC | Type of high school (private, city, state or federal) |
The dataset has a variable associated to each test which indicates the presence, absence or if the student was eliminated. Thus we can cross this variable with the test score to understand the missing values.
The below image shows the categorized score (0, >0 or missing) crossing with the presence variable, it shows that the missing scores are related with students who were eliminated or missed the test.
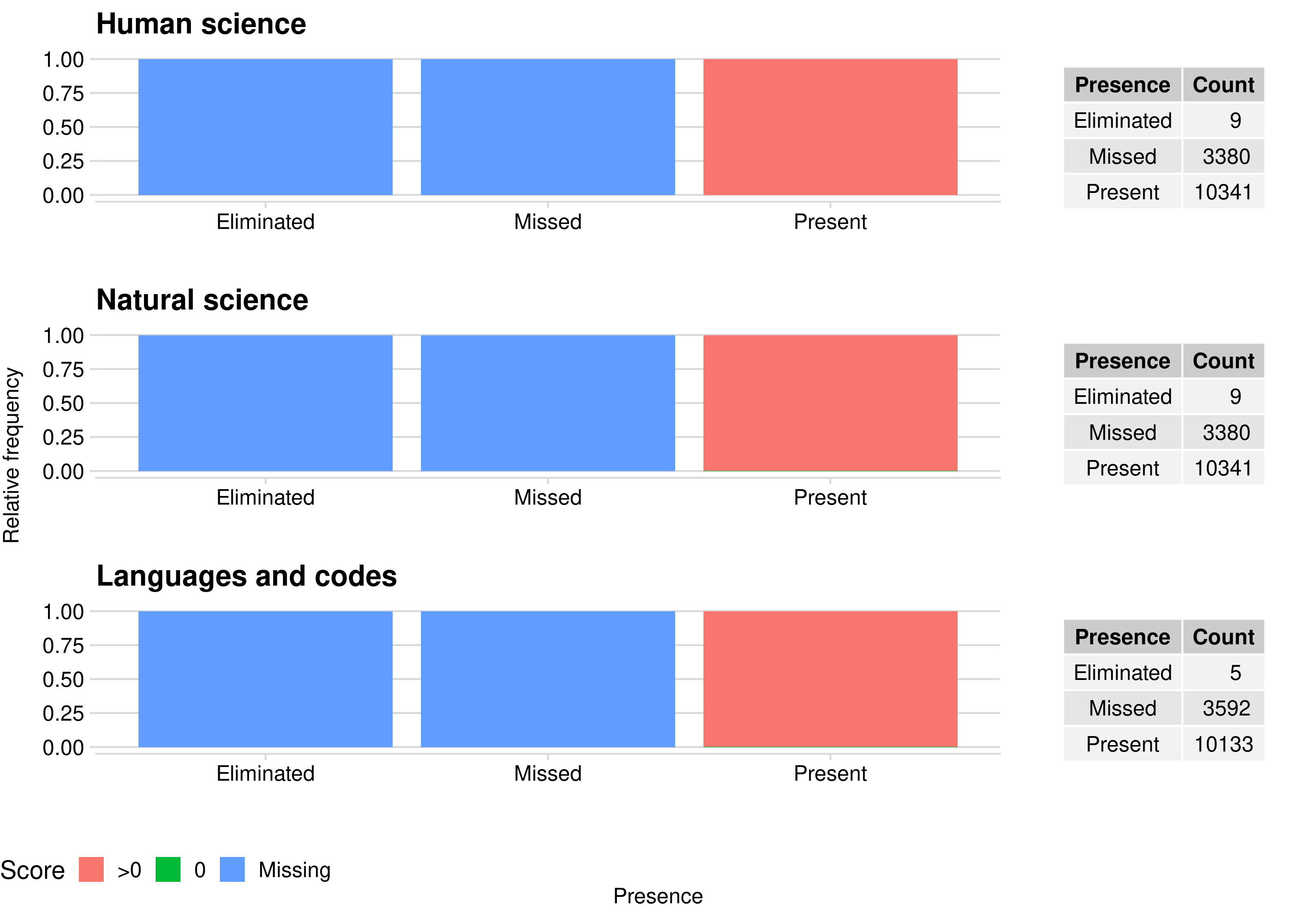
So, we have four possible situations:
- The student went to the test and achieve a positive score;
- The student went to the test and achieve a zero score;
- The student didn’t come to the test;
- The student was eliminated in the test.
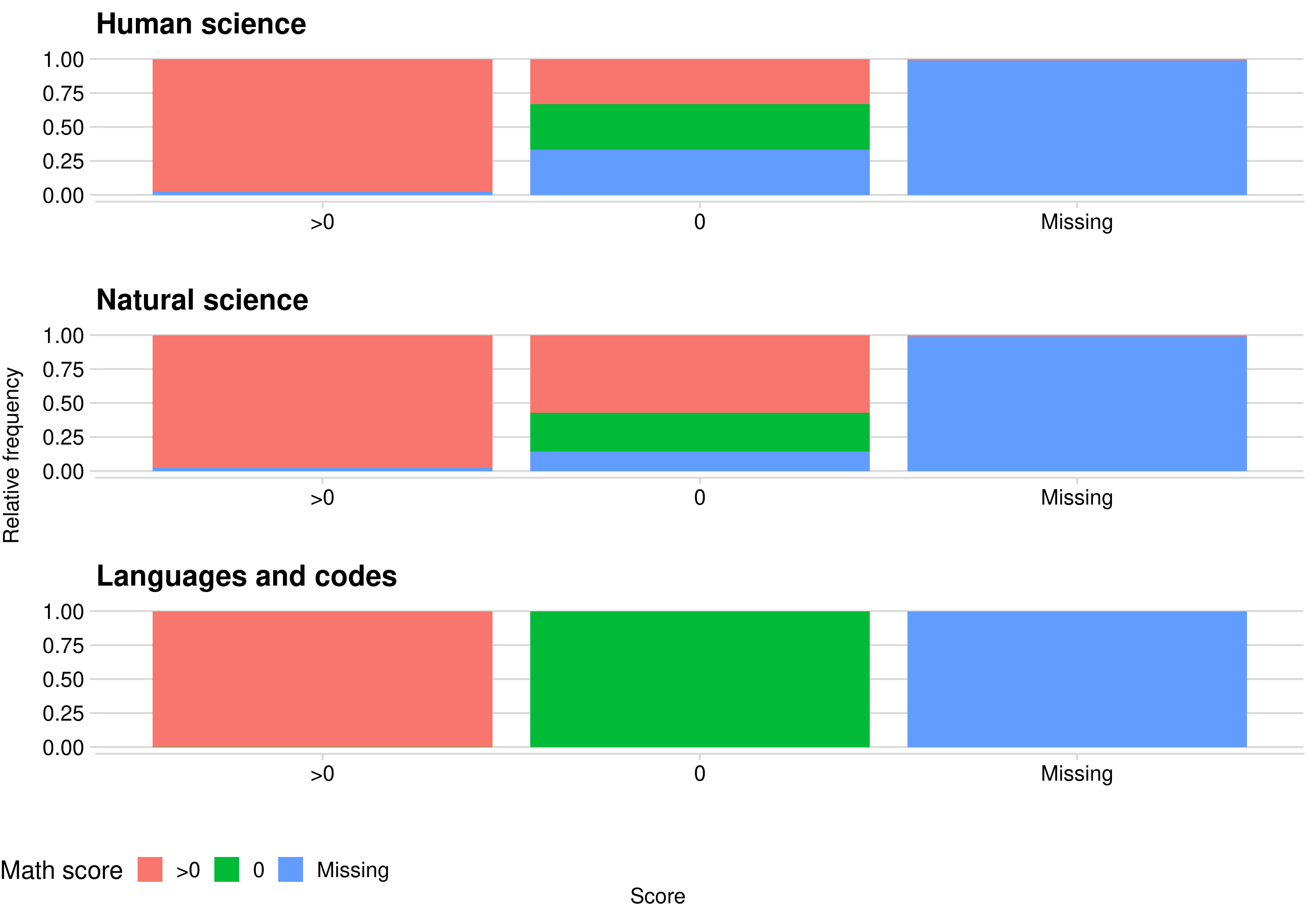
Looking at the relation between math score and tests score we can notice that most of the students who missed one of the tests (human science, natural science or languages) also missed the math test. It’s reasonable since the final score is a weighted mean of scores.
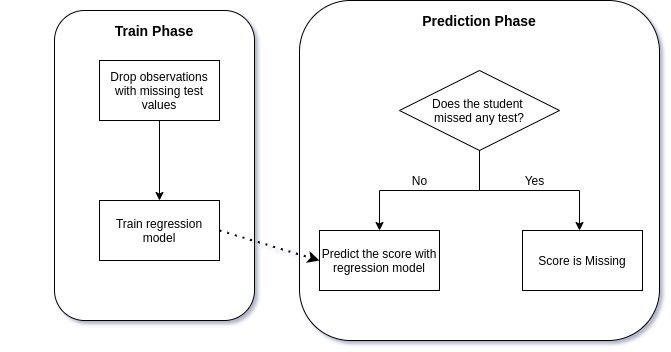
Knowing the relation between missing scores with math score we can propose a solution, a good one is to drop the observations with missing score and train a regression model. For the test data, if a student has missed one of the tests we can suppose that he will miss the math test.
For those who did all the tests we use the regression model to predict their math score, and for those who didn’t we can assume they missed the test.
The above process was my solution for this problem. For the regression model I trained a lasso and boosting (XGBoost) model, both achieved similar scores and was higher than the baseline for the selection process.
An even better solution that I did later was to create a classification model to predict the students who missed or were eliminated in the test and their score would be a missing value. For those who didn’t miss any test, the regression model should be used to predict their score.
Final considerations
It’s not trivial to handle with missing values in a predictive problem and is common to think in data imputation or drop the missing observations but, first of all it’s important to check how many observations are missing and how it’s related with the response variable and if it’s possible to get any insight about the problem.
Data science is about to solve problems based on data, it’s reasonable to understand the data first and then find a solution. It’s important to question the data and make hypotheses to find a good solution.
All the codes in this post and the solution for the challenge was designed using R and are available in this repository on GitHub.
Feel free to comment or to send me an email.